Architectures¶
Autoencoder¶
TODO: Description of Autoencoder use case and basic architecture. Figure from [1].
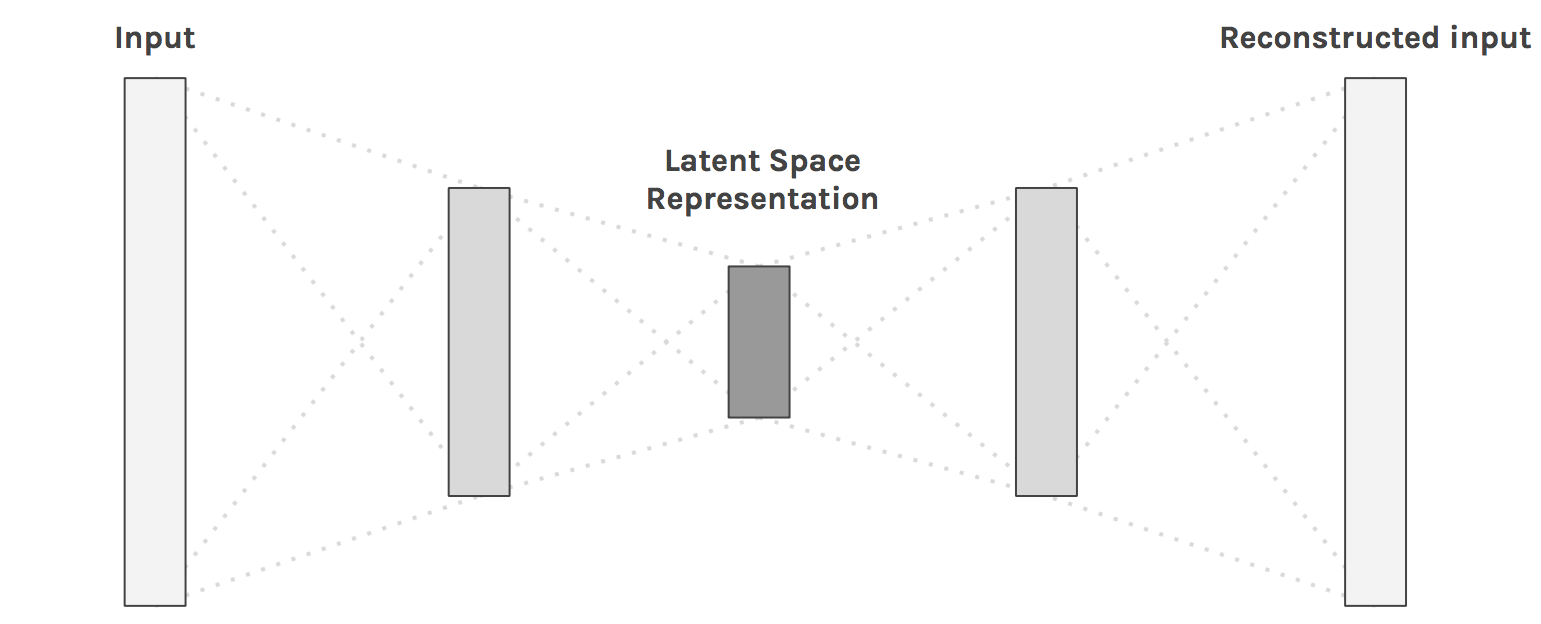
Model
An example implementation in PyTorch.
class Autoencoder(nn.Module):
def __init__(self, in_shape):
super().__init__()
c,h,w = in_shape
self.encoder = nn.Sequential(
nn.Linear(c*h*w, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 12),
nn.ReLU()
)
self.decoder = nn.Sequential(
nn.Linear(12, 64),
nn.ReLU(),
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, c*h*w),
nn.Sigmoid()
)
def forward(self, x):
bs,c,h,w = x.size()
x = x.view(bs, -1)
x = self.encoder(x)
x = self.decoder(x)
x = x.view(bs, c, h, w)
return x
Training
def train(net, loader, loss_func, optimizer):
net.train()
for inputs, _ in loader:
inputs = Variable(inputs)
output = net(inputs)
loss = loss_func(output, inputs)
optimizer.zero_grad()
loss.backward()
optimizer.step()
Further reading
CNN¶
TODO: Description of CNN use case and basic architecture. Figure from [2].
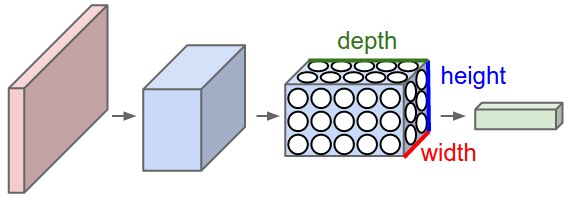
Model
An example implementation in PyTorch.
Training
Further reading
GAN¶
TODO: Description of GAN use case and basic architecture. Figure from [3].
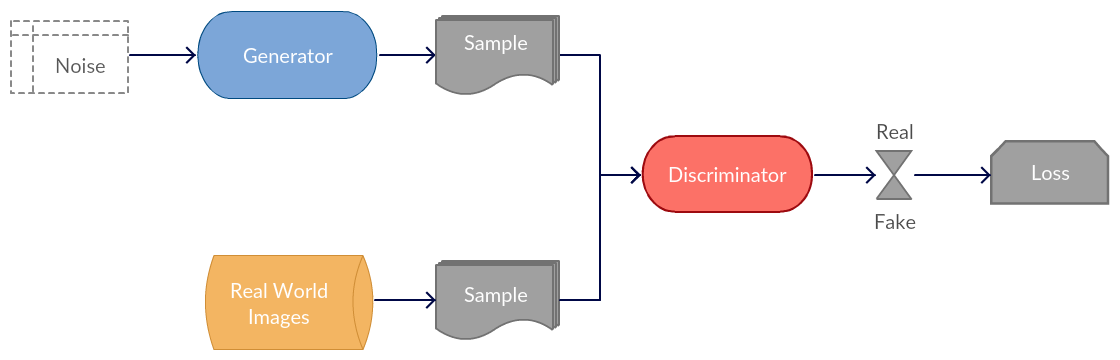
Model
TODO: An example implementation in PyTorch.
Training
TODO
Further reading
MLP¶
A Multi Layer Perceptron (MLP) is a neural network with only fully connected layers. Figure from [5].
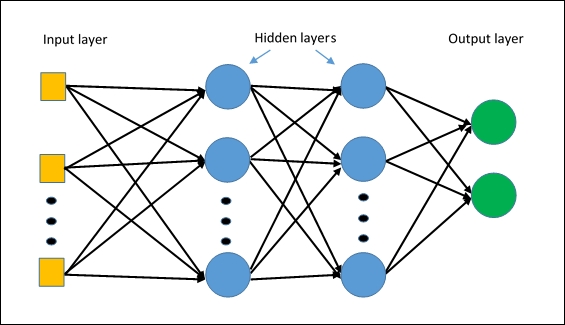
Model
An example implementation in Numpy or Pytorch?
TODO
Training
TODO
Further reading
TODO
RNN¶
Description of RNN use case and basic architecture.
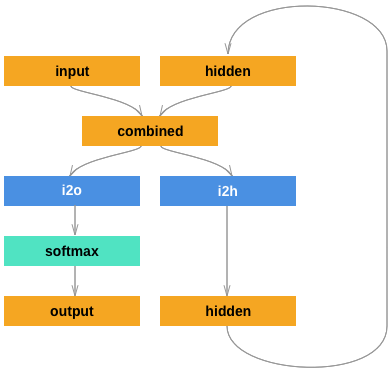
Model
class RNN(nn.Module):
def __init__(self, n_classes):
super().__init__()
self.hid_fc = nn.Linear(185, 128)
self.out_fc = nn.Linear(185, n_classes)
self.softmax = nn.LogSoftmax()
def forward(self, inputs, hidden):
inputs = inputs.view(1,-1)
combined = torch.cat([inputs, hidden], dim=1)
hid_out = self.hid_fc(combined)
out = self.out_fc(combined)
out = self.softmax(out)
return out, hid_out
Training
In this example, our input is a list of last names, where each name is a variable length array of one-hot encoded characters. Our target is is a list of indices representing the class (language) of the name.
- For each input name..
- Initialize the hidden vector
- Loop through the characters and predict the class
- Pass the final character’s prediction to the loss function
- Backprop and update the weights
def train(model, inputs, targets):
for i in range(len(inputs)):
target = Variable(targets[i])
name = inputs[i]
hidden = Variable(torch.zeros(1,128))
model.zero_grad()
for char in name:
input_ = Variable(torch.FloatTensor(char))
pred, hidden = model(input_, hidden)
loss = criterion(pred, target)
loss.backward()
for p in model.parameters():
p.data.add_(-.001, p.grad.data)
Further reading
VAE¶
Autoencoders can encode an input image to a latent vector and decode it, but they can’t generate novel images. Variational Autoencoders (VAE) solve this problem by adding a constraint: the latent vector representation should model a unit gaussian distribution. The Encoder returns the mean and variance of the learned gaussian. To generate a new image, we pass a new mean and variance to the Decoder. In other words, we «sample a latent vector» from the gaussian and pass it to the Decoder. It also improves network generalization and avoids memorization. Figure from [4].
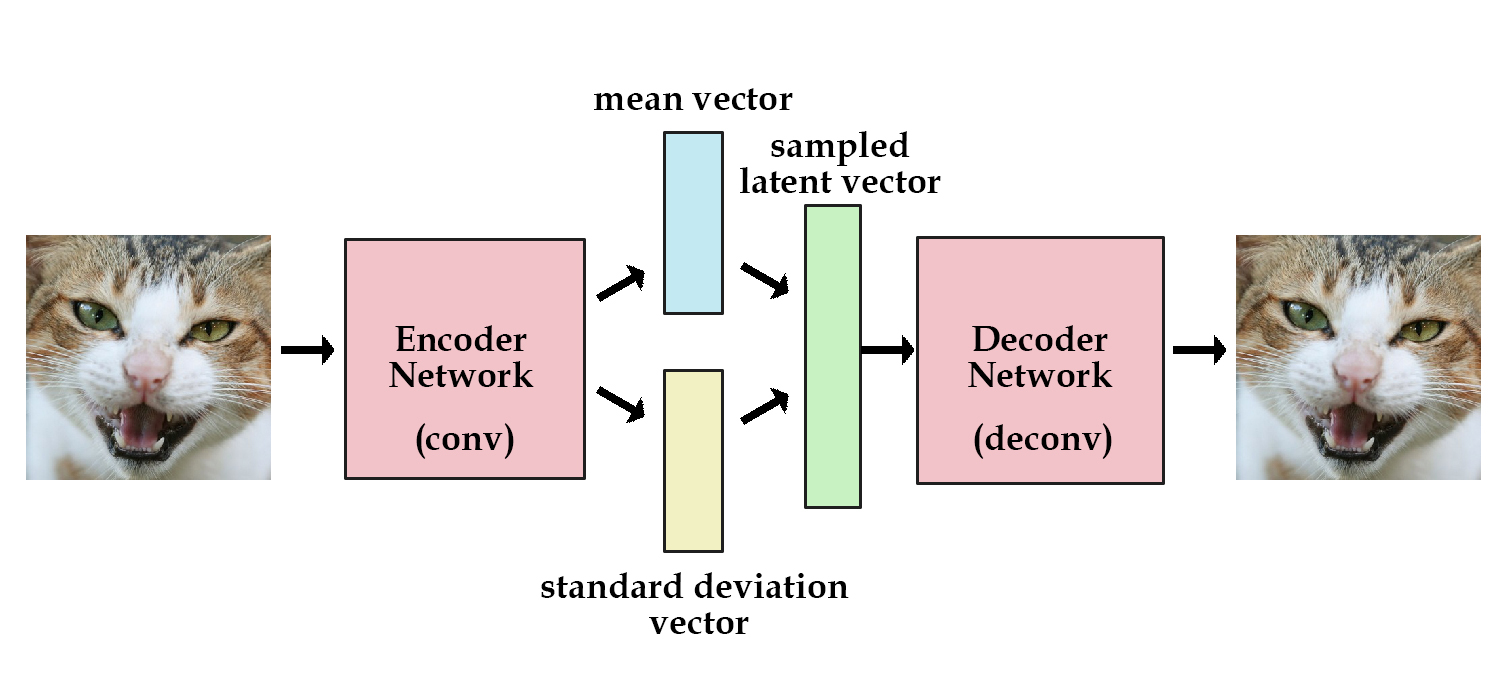
Loss Function
The VAE loss function combines reconstruction loss (e.g. Cross Entropy, MSE) with KL divergence.
def vae_loss(output, input, mean, logvar, loss_func):
recon_loss = loss_func(output, input)
kl_loss = torch.mean(0.5 * torch.sum(
torch.exp(logvar) + mean**2 - 1. - logvar, 1))
return recon_loss + kl_loss
Model
An example implementation in PyTorch of a Convolutional Variational Autoencoder.
class VAE(nn.Module):
def __init__(self, in_shape, n_latent):
super().__init__()
self.in_shape = in_shape
self.n_latent = n_latent
c,h,w = in_shape
self.z_dim = h//2**2 # receptive field downsampled 2 times
self.encoder = nn.Sequential(
nn.BatchNorm2d(c),
nn.Conv2d(c, 32, kernel_size=4, stride=2, padding=1), # 32, 16, 16
nn.BatchNorm2d(32),
nn.LeakyReLU(),
nn.Conv2d(32, 64, kernel_size=4, stride=2, padding=1), # 32, 8, 8
nn.BatchNorm2d(64),
nn.LeakyReLU(),
)
self.z_mean = nn.Linear(64 * self.z_dim**2, n_latent)
self.z_var = nn.Linear(64 * self.z_dim**2, n_latent)
self.z_develop = nn.Linear(n_latent, 64 * self.z_dim**2)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=0),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.ConvTranspose2d(32, 1, kernel_size=3, stride=2, padding=1),
CenterCrop(h,w),
nn.Sigmoid()
)
def sample_z(self, mean, logvar):
stddev = torch.exp(0.5 * logvar)
noise = Variable(torch.randn(stddev.size()))
return (noise * stddev) + mean
def encode(self, x):
x = self.encoder(x)
x = x.view(x.size(0), -1)
mean = self.z_mean(x)
var = self.z_var(x)
return mean, var
def decode(self, z):
out = self.z_develop(z)
out = out.view(z.size(0), 64, self.z_dim, self.z_dim)
out = self.decoder(out)
return out
def forward(self, x):
mean, logvar = self.encode(x)
z = self.sample_z(mean, logvar)
out = self.decode(z)
return out, mean, logvar
Training
def train(model, loader, loss_func, optimizer):
model.train()
for inputs, _ in loader:
inputs = Variable(inputs)
output, mean, logvar = model(inputs)
loss = vae_loss(output, inputs, mean, logvar, loss_func)
optimizer.zero_grad()
loss.backward()
optimizer.step()
Further reading
References
| [1] | https://hackernoon.com/autoencoders-deep-learning-bits-1-11731e200694 |
| [2] | http://cs231n.github.io/convolutional-networks |
| [3] | http://guertl.me/post/162759264070/generative-adversarial-networks |
| [4] | http://kvfrans.com/variational-autoencoders-explained |